Understanding AI often feels confusing because terms like machine learning, deep learning, transformers, and NLP are used interchangeably. In this guide, you’ll see how they actually connect — step by step — and how transformers became the foundation of modern LLMs like ChatGPT. If you don’t understand the structure, AI feels abstract; once you do, everything becomes logical...
Understanding AI often feels confusing because terms like machine learning, deep learning, transformers, and NLP are used interchangeably. In this guide, you’ll see how they actually connect — step by step — and how transformers became the foundation of modern LLMs like ChatGPT. If you don’t understand the structure, AI feels abstract; once you do, everything becomes logical...





AI Isn’t Magic — What Is It Really Made Of? Artificial Intelligence, Explained Clearly

Frank Arellano
Founder of Plexotrade LLCIf you are trying to understand Large Language Models (LLMs), there is one confusion you must clear out immediately:
Artificial Intelligence → Machine Learning → Neural Networks → Deep Neural Networks / Deep Learning → Transformer Architecture
(NLP is a separate applied discipline that operates across the stack)
- They are layers of a stack.
- Each one builds on top of the previous one.
- Each one plays a different role.
If you mix them together, everything feels vague. Why do most explanations of AI feel confusing? Because they skip the structure. Once you see the hierarchy clearly, everything becomes logical.
How Transformers Gave Rise to ChatGPT and Modern Language Models
Before transformers, AI models already existed and were actively used in language tasks. Systems like recurrent neural networks (RNNs) and long short-term memory networks (LSTMs) powered:
- Translation
- Speech recognition
- and text prediction.
However, they struggled with linguistic long-range dependencies and were difficult to scale efficiently. The paradigm shifted in 2017 when Google introduced the Transformer architecture in the paper “Attention Is All You Need.”
By replacing recurrence with self-attention, transformers enabled massive parallelization, better context handling, and unprecedented scalability. This architectural shift fundamentally changed AI, making today’s large language models possible.
Long-range dependencies are situations where the meaning of a word depends on another word that appears far away in the sentence. In human language, important relationships are often separated by many words.
For example:
"The book that the professor who won the award recommended was fascinating."
The word “was” depends on “book”, not on “professor” or “award.” But “book” appears far earlier in the sentence. That distance is a long-range dependency.
Transformers use self-attention, which allows every word to directly “look at” every other word in the sentence — instantly. Instead of passing information step by step, the model calculates relationships in parallel.
That means:
- “Was” can directly attend to “book”
- Even if 30 words separate them
- Without losing information over distance
1. Transformer Is a Deep Neural Network Architecture
A transformer is a specific design of a deep neural network.
It defines:
- How data flows through layers
- How attention mechanisms work
- How relationships between tokens are modeled
It is not separate from neural networks.
It is a type of neural network.
A transformer is not outside neural networks. It is a specialized form of them.
Its defining innovation is self-attention, which allows the model to weigh the importance of every token relative to every other token in a sequence.
2. Deep Learning Uses Deep Neural Networks
Deep learning refers to neural networks with multiple layers that learn hierarchical representations from data.
The word “deep” simply means:
- Many stacked layers
- Layer-by-layer feature abstraction
- Progressive pattern extraction
Transformers are deep neural networks based on attention mechanisms rather than recurrence or convolution, designed to model complex patterns in sequences.
Depth allows abstraction. Abstraction allows intelligence.
3. Neural Networks Are Part of Machine Learning
Machine learning is the broader field where models learn patterns from data instead of being explicitly programmed.
Deep learning is a subset of machine learning focused specifically on neural networks.
So the hierarchy begins to form:
- Machine Learning (scientific field and methodological framework)
- Neural Networks (family of machine learning models)
- Deep Neural Networks / Deep Learning (a neural network modeling paradigm within machine learning)
- Transformer Architecture (specific deep neural network architecture)
Machine learning is the umbrella. Deep learning is a branch. Transformers are one design inside that branch.
This simple analogy can help:
Machine Learning = civil engineering field
Neural Networks = type of building material
Deep Learning = skyscraper construction methods
Transformer = specific skyscraper design
4. How This Stack Creates LLMs
A Large Language Model (LLM) is created when:
- A transformer architecture
- Is trained using machine learning optimization techniques
- On massive amounts of text data
- Using large scale computational resources
The full stack looks like this:
| Layer | Role |
| Machine Learning | Provides optimization methods and learning framework |
| Neural Networks | Provide the mathematical modeling framework |
| Deep Neural Networks / Deep Learning | Uses deep neural networks to learn hierarchical representations |
| Transformer Architecture | Defines the specific neural network design |
| Large-Scale Training | Pretrains the transformer on massive datasets using large-scale compute, producing a foundation model that can be adapted or fine-tuned into an LLM. |
In short:
Transformer Architecture + Training Objective (e.g., next token prediction) + Massive Dataset + Large Scale Compute = LLM
Architecture without data is empty. Data without compute is inert. Compute without structure is useless.
These three forces — data, architecture, and computing power — have converged at precisely the right moment to make highly capable large language models possible.
Massive datasets provide the raw material, transformer architectures provide the structure, and modern processors supply the computational strength required to train them at scale.
In particular, processors designed for parallel computing are essential, because training these models involves performing billions of mathematical operations simultaneously.
Today, the most recognized name in AI computing hardware is Nvidia, whose GPUs have become the backbone of large-scale AI training.
To see practical implementation at scale, look at how Salesforce applies AI in its ecosystem:
- What Is Digital Labor? — Intelligent AI Agents
- The Agent-First Blueprint — 5 Characteristics of an Agentforce Company
A GPT (Generative Pretrained Transformer) is a specific type of transformer based language model trained with a generative objective (a family of LLMs).
Where NLP Enters the Picture
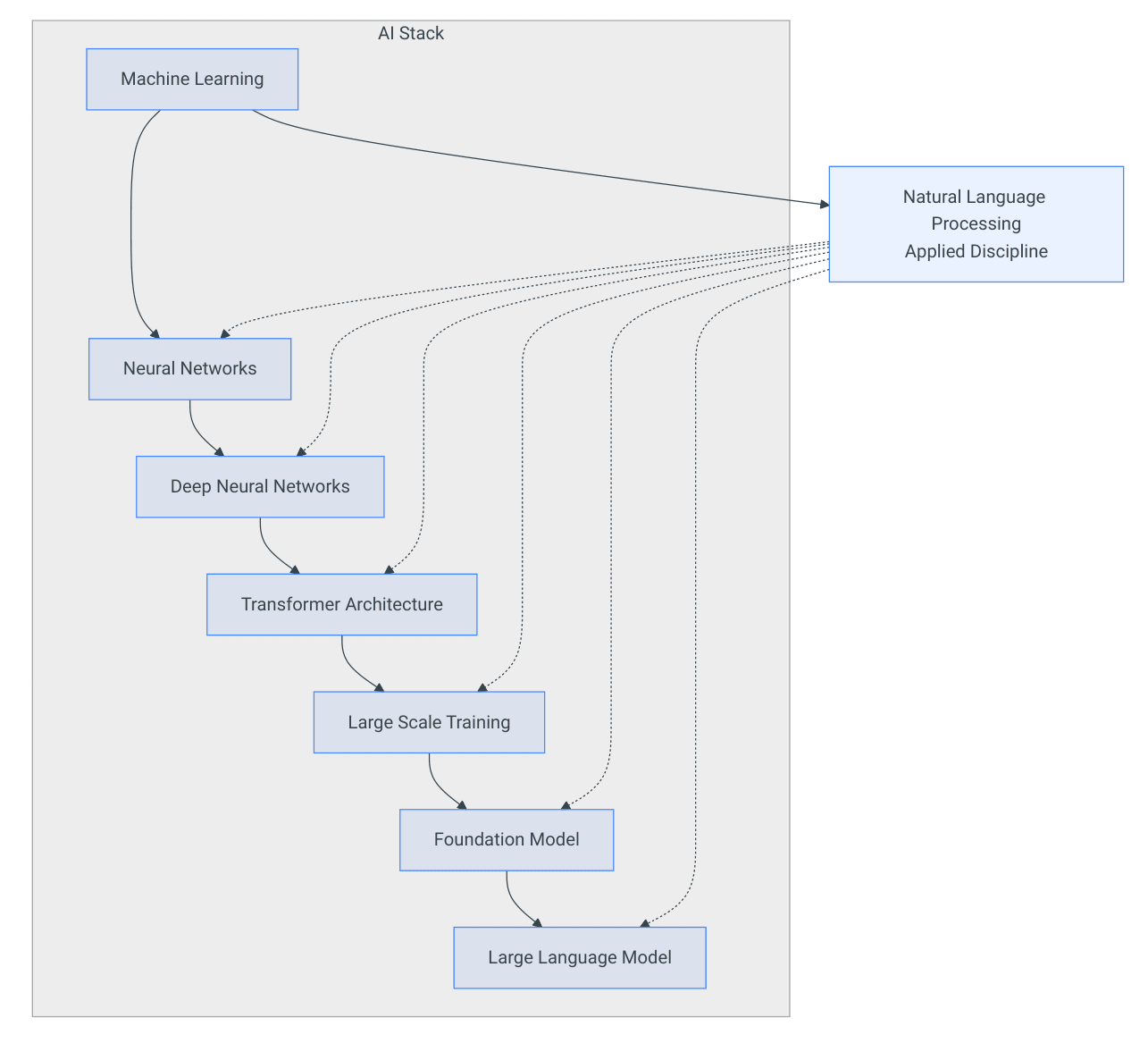
Now we introduce another layer:
Natural Language Processing (NLP)
Think of NLP as the language focused field where machine learning methods are applied to understand, analyze, and generate human language.
Techniques from NLP are applied before training, during training, and after training.
NLP is not the engine. It defines how the engine interacts with language.
1. Data Preparation and Tokenization
Before training starts, NLP techniques process human language into a form models can learn from.
Examples include:
- Text cleaning and normalization
- Sentence segmentation
- Tokenization into subwords or tokens
- Handling punctuation, casing, multilingual text
This is classical NLP preprocessing.
Without this stage, raw language is too irregular and noisy for effective learning.
Language must be structured before it can be learned.
2. Language Representation (Embeddings)
NLP research drives how words or tokens are represented numerically.
Transformers use embeddings that capture semantic relationships between words.
For example:
“King” and “queen” end up close in vector space because of similar contextual usage.
This idea comes from NLP representation learning research.
Embeddings translate meaning into geometry.
Meaning becomes distance in vector space.
3. Training Objective Design
The training task itself originates from NLP.
Next-token prediction is fundamentally a language modeling task — a core NLP problem.
Other NLP inspired objectives include:
- Masked language modeling
- Sequence-to-sequence prediction
- Text completion
The architecture learns whatever objective we define.
NLP defines that objective for language tasks.
The objective determines what intelligence emerges.
4. Model Architecture Design
Transformers were originally introduced for NLP tasks such as translation.
Attention was introduced earlier in neural machine translation and later became the core mechanism of the transformer architecture.
So NLP influenced not only the training but the architecture itself.
The transformer was born to solve language problems.
5. Instruction Tuning and Alignment
When training conversational models, additional NLP datasets are used:
- Human dialogue datasets
- Question answering datasets
- Summarization examples
These are all NLP tasks that shape the model’s behavior.
This stage aligns raw language modeling ability with useful interaction.
Raw prediction becomes structured conversation.
6. Evaluation and Benchmarking
NLP research provides benchmarks and evaluation frameworks.
- Language understanding benchmarks
- Translation accuracy
- Reasoning and comprehension tasks
Without evaluation frameworks from NLP, we would not know whether the model truly understands language.
Measurement defines progress.
Simple Mental Model
To make everything concrete:
- Machine learning provides learning methods.
- Neural networks provide the mathematical structure.
- Transformer provides the new architecture.
- NLP defines how language data is processed, trained on, and evaluated.
So NLP enters:
- Before training (data processing)
- During training (objectives and representation)
- After training (evaluation and alignment)
Machine learning teaches models to learn. NLP teaches them what it means to understand language.
How an LLM Runs in Production
A Large Language Model operates as part of a layered software system where different components handle execution, performance, and interaction. The trained transformer itself is not a standalone application. Instead, it is activated and controlled by an inference engine, which acts as the runtime environment responsible for turning model weights into live responses.
When a request arrives, the inference engine loads the transformer model and manages how computations are performed on GPUs. It allocates memory, schedules workloads, executes the forward pass of the neural network, and generates tokens step by step according to defined sampling strategies. Surrounding infrastructure such as APIs or orchestration platforms manages traffic and scaling, while the inference engine focuses specifically on efficient model execution.
Conceptually, the internal structure of the inference runtime can be understood as:
Inference Engine
├── Transformer Model
├── GPU Execution Layer
├── Memory Manager
├── Scheduler
└── Sampling Logic
→ The inference engine includes the orchestration runtime logic.
→ The transformer model contains the trained weight files and the architecture configuration.
→ The sampling logic manages the token selection strategy.
Together, these components ensure that incoming text is processed through the transformer architecture, executed on hardware efficiently, and returned as generated output in real time.
Final Perspective
When someone says “LLM,” they are referring to the final product of an entire layered stack.
Remove one layer, and the system collapses.
Keep the hierarchy clear, and the architecture becomes simple:
Artificial Intelligence → Machine Learning → Neural Networks → Deep Neural Networks / Deep Learning → Transformer Architecture → Large Scale Training → Foundation Model → LLM
Add NLP across the entire process, and the model becomes language aware.
Machine learning is the discipline used to build the car. Transformers are the engine inside it. Data is the fuel that makes it run. NLP is the navigation system telling it where to go.
→ This analogy helps illustrate the clear distinction between methods, architectures, and application domains.
Key References
-
Attention Is All You Need
Original research paper introducing the Transformer architecture and the self-attention mechanism that powers modern large language models. -
Language Models are Few Shot Learners
OpenAI paper presenting GPT-3 and demonstrating how large-scale language models can perform tasks with minimal examples. -
Scaling Laws for Neural Language Models
Research explaining how model performance improves as training data, compute, and model size increase. -
Speech and Language Processing (Stanford NLP Book) — Daniel Jurafsky & James H. Martin
Comprehensive academic textbook covering the foundations of natural language processing, language modeling, and modern NLP techniques. -
On the Opportunities and Risks of Foundation Models
Stanford research paper introducing the concept of foundation models and analyzing their societal and technical implications. -
The Illustrated Transformer — Jay Alammar
A widely used visual explanation of the Transformer architecture and attention mechanisms.





Frank
February 26, 2026AI empowers developers to move beyond hard coded integrations and become strategic enablers of the technology.
Frank
February 25, 2026AI allows a team of two to operate like a team of 20.
Frank
February 25, 2026AI is here to augment human capabilities, shifting the conversation from fear of job displacement to excitement about job transformation. By augmenting human labor with artificial intelligence, we unlock lower costs, faster innovation, and a competitive edge that others can’t match.
Frank
February 25, 2026AI isn’t here to replace us, it’s here to fix the issues that arise when we try to move from point A to point B, C, or beyond. It addresses the challenges, limitations, errors, and inefficiencies that have accompanied human progress throughout history — up to this moment, when AI becomes part of the solution.